A fast run for impatient users
(A) Installation
Click here to download and install WGAViewer onto your computer.
(B) An example: loading an example dataset
Start the WGAViewer program. Click on menu “File->Open an example dataset”. Select "post-annotation dataset", and then select "CHAVI_SETPOINT_SCIENCE.wga" (Figure 3.1-1). Follow the instructions on the "Top hits" panel.
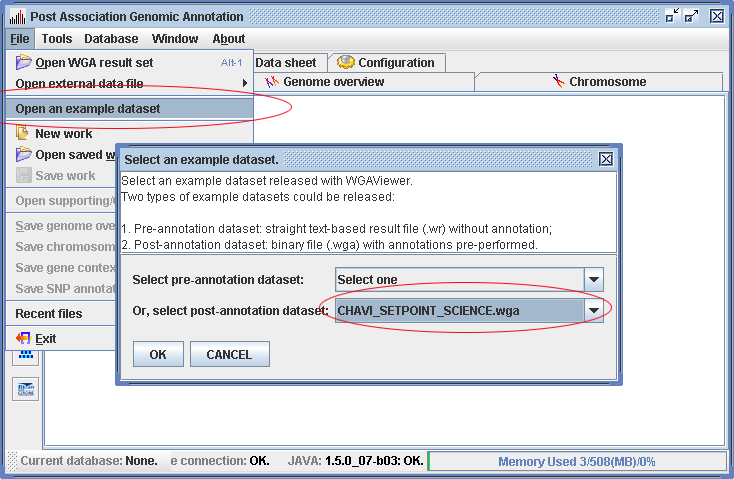
Figure 3.1-1 Load example dataset. (Click to enlarge)
(C) Real-world data: loading your dataset generated from PLINK (or other software with similar flat-text outputs)
WGAViewer supports the outputs from PLINK (Purcell et al. 2007) . To open PLINK output, click on menu “File->Open external data file->Open PLINK output”. These processes will generate and save a “.wr” input file for WGAViewer.
Figure 3.2.1-1 shows an example of the configuration of this process. In this example we load a WGA result set generated by linear regression analysis from PLINK.
[1] The external data set to be loaded should be separated by either space or tab key.
[2] It should have one row of header line indicating each column name, and at least one column for SNP and one column for P value (as shown from Figure 3.2.1-1).
[3] Every data row should have the same number of columns with the header row, otherwise the program will throw an error message.
[4] A standard MAP file (or PLINK BIM file) is also required. A MAP file has no header line, and has four columns: chromosome, SNP, genetic distance (could be 0, will not be used), and physical chromosomal location (could be from older genome build, will be annotated later).
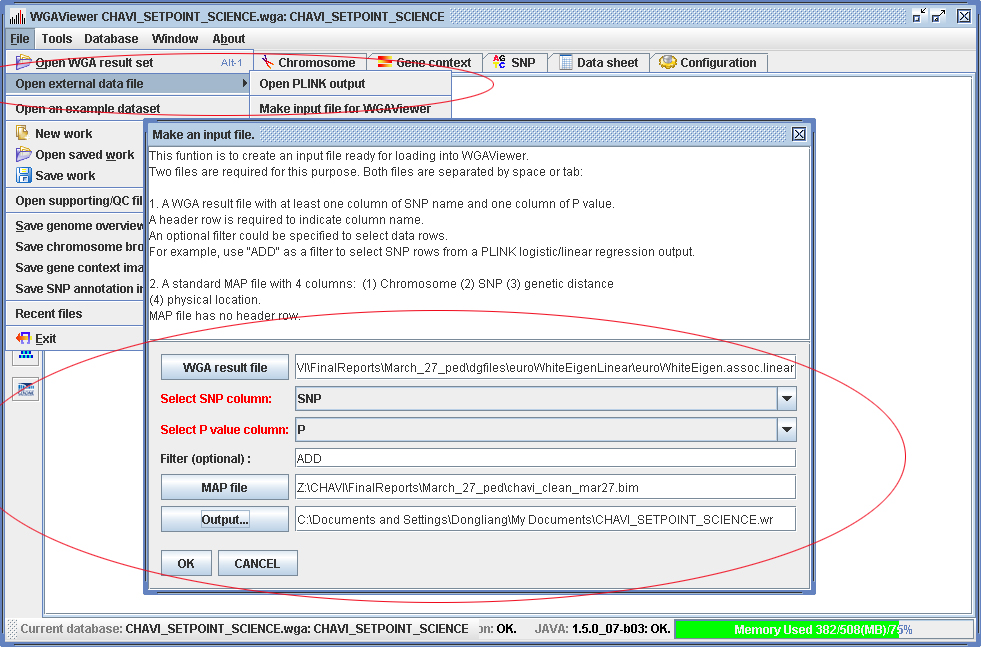
Figure 3.2.1-1 Load external data file (Click to enlarge)
(D) Annotating your loaded dataset
Click on menu "Tool -> Top hits" to annotate the SNPs with the lowest P values. Follow the instructions, or, for details see here.