Searching for association across multiple databases
It is reasonable to assume that some polymorphisms will influence multiple related phenotypes, for example a single polymorphism might influence multiple autoimmune disease, resistance to different infectious agents, or different neuropsychiatric conditions. For this reason it is convenient to be able to identify polymorphisms that show evidence of association, at a user defined threshold, in two or more datasets.
To do this, click on menu “Database -> Database cross reference” and a dialog for searching parameters will present itself (Figure 3.8.2-1). The most important parameter here that needs to be specified should be the P value level that will be used as a cutoff for including into the report. In the example shown (Figure 3.8.2-1), only SNPs with P values equal to or lower than 0.05 in all core and reference databases will be included in the consequent report. The report will be sorted by the P values in the core dataset. One can also specify a brief annotation on a subset (or all) of the cross-referenced SNPs, for example, annotating the top 100 (sorted by core dataset P values) as shown from Figure 3.8.2-1.
his will then give a report as illustrated in Figure 3.8.2-2. The columns from left to right are: SNP name, chromosome, SNP type, the closest gene, the distance to the closest gene, the distance to the closest exon, P values in the core dataset, and P values in the reference dataset. The SNP name is clickable and will launch an annotation for the surrounding chromosome region.
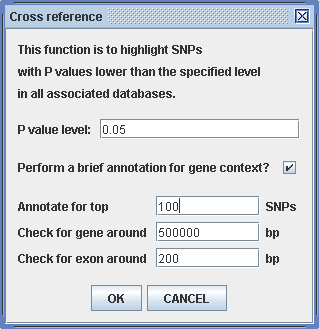
Figure 3.8.2-1. Parameters for cross reference searching.
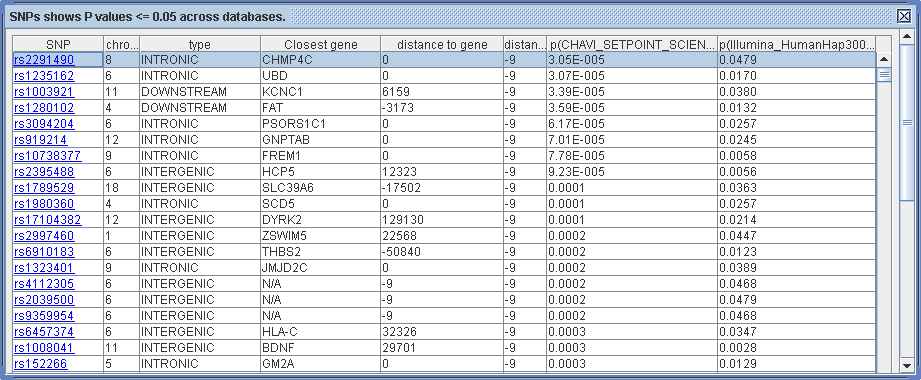
Figure 3.8.2-2. Reports for cross reference. (Click to enlarge)
Related topic: Plotting multiple databases