Multiple databases
This function suite has been designed to easily compare between multiple databases. These databases can be replication cohorts, cohorts with the same phenotype but different SNP sets, cohorts with related phenotypes, or the same cohort with different phenotypes. The aim of this function is to easily obtain concurrent or supporting evidence.
To illustrate this function, we add a simulated dataset (Illumina_HumanHap300_sim.wr) into the loaded CHAVI_SETPOINT_SCIENCE.wga set. Each database to be loaded has to be first transformed into WGAViewer .wr file as discussed in section “data input”.
Click on menu “ Database -> Database manager ”. And then load the simulated dataset from folder “./examples” by clicking “ Add a reference dataset ” button in the interface of database manager (circled in Figure 3.8-1).
One has the option to add or remove specific reference databases to list alongside with the core database. One also has the option to edit the description for each database as shown from Figure 3.8-1.
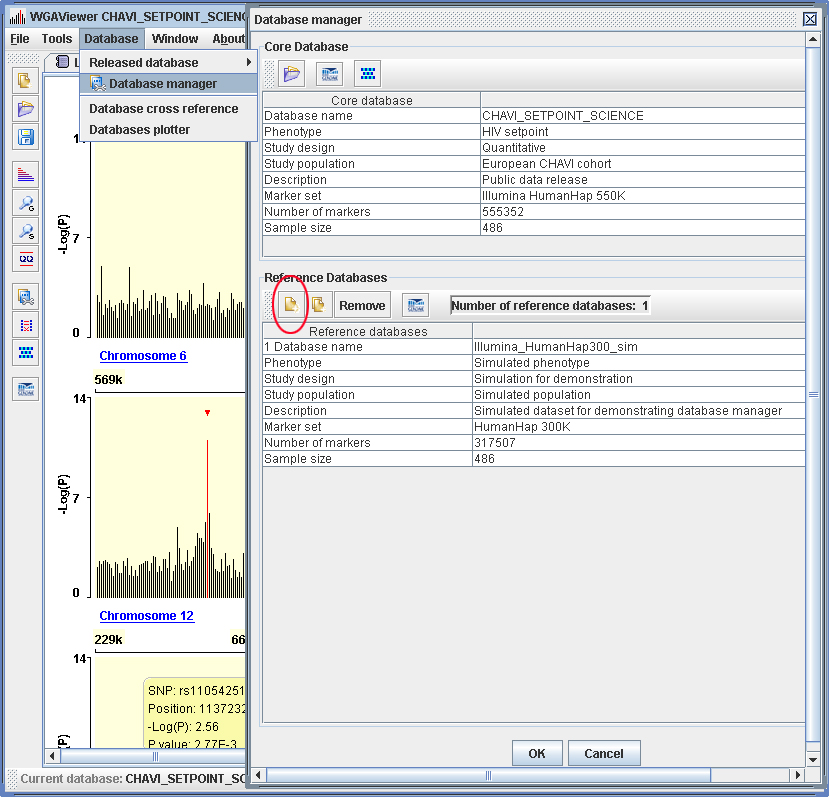
Figure 3.8-1. Loading a supporting database. (Click to enlarge)
Next: Plotting multiple databases; Searching for concurrent evidence